VIT
Composition
It comprises of many layers.
- Layer -> takes an input, performs a function on it, returns an output
- Block -> collection of layers
- Architecture/Model -> collection of blocks
Architecture
- Embeddings -> images turned into patches (learnable representations)
- Norm -> Layer normalization for regularization
- Multi-Head Attention
- MLP -> collection of feedforward layers with an activation function GELU and dropout
- Transformer Encoder -> two skip connections present. layer's inputs are fed to immediate layers as well as subsequent layers
- MLP Head -> output layer/ it converts learned features into a class output
Math
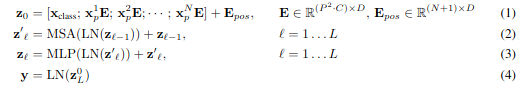
Architecture Flow
Calculating patch embedding input and output shapes by hand
height = 224 # H
width = 224 # W
color_channels = 3 # C
patch_size = 16 # P
number_of_patches = (height * width) / patch_size**2
# size of single image
embedding_layer_input_shape = (height, width, color_channels)
#output shape after being converted
embedding_layer_input_shape = (number_of_patches, (patch_size**2 * color_channels))
Turning a single image into patches with nn.Conv2d()
from torch import nn
patch_size = 16
conv2d = nn.Conv2d(in_channels=3,
out_channels=768, # From Table 1: This is the hidden size
kernel_size=patch_size,
stride=patch_size,
padding=0
)
# (embedding_dim, height, width) -> [768, 14, 14]
# unsqueeze(0) -> (batch, embedding_dim, feature_map_height, feature_map_width) -> [1, 768, 14, 14]
Flattening the patch embedding with torch.nn.Flatten()
The spatial dimensions are what needs to be flattened eg. feature_map_height and feature_map_width which are at pos 2 and 3 in the output
flatten = nn.Flatten(start_dim=2, end_dim=3) # flatten feature_map_height and feature_map_width
- current shape: (1, 768, 196)
- desired: (1, 196, 768)
image_out_of_conv_flattened_reshaped = image_out_of_conv_flattened.permute(0, 2, 1)
# [batch_size, P^2*C, N] -> [batch_size, N, P^2*C]
[!NOTE] The original Transformer architecture was designed to work with text. The Vision Transformer architecture (ViT) had the goal of using the original Transformer for images. This is why the input to the ViT architecture is processed in the way it is. We're essentially taking a 2D image and formatting it so it appears as a 1D sequence of text.
Turning the ViT patch embedding layer into a PyTorch module
import torch
import torch.nn as nn
class PatchEmbedding(nn.Module):
def __init__(self, in_channels=3, embedding_dim=768, patch_size=16):
super().__init__()
self.in_channels = in_channels
self.patch_size = patch_size
self.embedding_dim = embedding_dim
self.conv = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.embedding_dim,
kernel_size=self.patch_size,
stride=self.patch_size,
padding=0
)
self.flatten = nn.Flatten(start_dim=2, end_dim=3)
def forward(self, X):
assert X.shape[-1] % self.patch_size == 0, "Input dimensions must be divisible"
out_conv = self.conv(X.unsqueeze(0)) # [1, 768, 14, 14]
out_conv = self.flatten(out_conv) # [1, 768, 196]
out_conv = out_conv.permute(0, 2, 1) # [1, 196, 768]
return out_conv
Creating class token embedding
# Get the batch size and embedding dimension
batch_size = patch_embedded_image.shape[0]
embedding_dimension = patch_embedded_image.shape[-1]
# Create the class token embedding as a learnable parameter that shares the same size as the embedding dimension (D)
class_token = nn.Parameter(torch.ones(batch_size, 1, embedding_dimension), # [batch_size, number_of_tokens, embedding_dimension]
requires_grad=True) # make sure the embedding is learnable
# Print the class_token shape
print(f"Class token shape: {class_token.shape} -> [batch_size, number_of_tokens, embedding_dimension]")
- We prepend the class token to the patched images
patch_embedded_image_with_class_embedding = torch.cat((class_token, patched_embedded_image), dim=1) # concat on the first dimension
Creating the position embedding
# Calculate N (number of patches)
number_of_patches = int((height * width) / patch_size**2)
# Get embedding dimension
embedding_dimension = patch_embedded_image_with_class_embedding.shape[2]
# Create the learnable 1D position embedding
position_embedding = nn.Parameter(torch.ones(1,
number_of_patches+1,
embedding_dimension),
requires_grad=True) # make sure it's learnable
print(f"Position embedding shape: {position_embedding.shape} -> [batch_size, number_of_patches, embedding_dimension]")
- Add the position embedding to the patch and class token embedding
patch_and_position_embedding = patch_embedded_image_with_class_embedding + position_embedding
Putting it all together: from image to embedding
set_seeds()
# 1. Set patch size
patch_size = 16
# 2. Print shape of original image tensor and get the image dimensions
print(f"Image tensor shape: {image.shape}")
height, width = image.shape[1], image.shape[2]
# 3. Get image tensor and add batch dimension
x = image.unsqueeze(0)
print(f"Input image with batch dimension shape: {x.shape}")
# 4. Create patch embedding layer
patch_embedding_layer = PatchEmbedding(in_channels=3,
patch_size=patch_size,
embedding_dim=768)
# 5. Pass image through patch embedding layer
patch_embedding = patch_embedding_layer(x)
print(f"Patching embedding shape: {patch_embedding.shape}")
# 6. Create class token embedding
batch_size = patch_embedding.shape[0]
embedding_dimension = patch_embedding.shape[-1]
class_token = nn.Parameter(torch.ones(batch_size, 1, embedding_dimension),
requires_grad=True) # make sure it's learnable
print(f"Class token embedding shape: {class_token.shape}")
# 7. Prepend class token embedding to patch embedding
patch_embedding_class_token = torch.cat((class_token, patch_embedding), dim=1)
print(f"Patch embedding with class token shape: {patch_embedding_class_token.shape}")
# 8. Create position embedding
number_of_patches = int((height * width) / patch_size**2)
position_embedding = nn.Parameter(torch.ones(1, number_of_patches+1, embedding_dimension),
requires_grad=True) # make sure it's learnable
# 9. Add position embedding to patch embedding with class token
patch_and_position_embedding = patch_embedding_class_token + position_embedding
print(f"Patch and position embedding shape: {patch_and_position_embedding.shape}")
Replication Equation 2 with Pytorch Layers
import torch
import torch.nn as nn
class MultiheadSelfAttentionBlock(nn.Module):
def __init__(self, embed_dim=768, num_heads=12, dropout=0, batch_first=True):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.layer = nn.LayerNorm(normalized_shapeself.embed_dim)
self.attention = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout, batch_first=batch_first)
def forward(self, X):
X = self.layer(X)
X, _ = self.attention(
query=X,
key=X,
value=X,
need_weights=False
)
return X
- An instance is created and the
patch_and_position_embeddingis passed in
multihead_self_attention_block = MultiheadSelfAttentionBlock(embedding_dim, num_heads=12)
multihead_sef_attention_block(patch_and_position_embedding)
MultiLayer Peceptron
class MLPBlock(nn.Module):
def __init__(self, embed_dim=768, mlp_size=3072, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.dropout = nn.Dropout(p=dropout)
self.linear1 = nn.Linear(in_features=embed_dim, out_features=mlp_size)
self.linear2 = nn.Linear(in_features=mlp_size, out_features=embed_dim)
self.gelu = nn.GELU()
self.norm = nn.LayerNorm(normalized_shape=embed_dim)
self.seq = nn.Sequential(
self.linear1,
self.gelu,
self.dropout,
self.linear2,
self.dropout
)
def forward(self, X):
X = self.norm(X)
X = self.seq(X)
return X
- Instance
# Create an instance of MLPBlock
mlp_block = MLPBlock(embedding_dim=768, # from Table 1
mlp_size=3072, # from Table 1
dropout=0.1) # from Table 3
# Pass output of MSABlock through MLPBlock
patched_image_through_mlp_block = mlp_block(patched_image_through_msa_block)
print(f"Input shape of MLP block: {patched_image_through_msa_block.shape}")
print(f"Output shape MLP block: {patched_image_through_mlp_block.shape}")
Create the Transformer Encoder
class TransformerEncoderBlock(nn.Module):
def __init__(self, embed_dim=768, num_heads=12, att_dropout=0, batch_first=True, mlp_size=3072, mlp_dropout=0.1, MSA: MutliheadSelfAttentionBlock, MLP: MLPBlock):
super().__init__()
self.embed_dim embed_dim
self.norm = nn.LayerNorm(normalized_shape=embed_dim)
self.attention = MSA(embed_dim, num_heads, att_dropout, batch_first)
self.mlp = MLP(embed_dim, mlp_size, mlp_dropout)
def forward(self, X):
X = self.attention(X) + X
X = self.mlp(X) + X
return X
Putting it all together to create ViT
class ViT(nn.Module):
def __init__(self, img_size=224, in_channels=3, num_layers=12, hidden_size=768, mlp_size=3072, num_heads=12, patch_size=16, att_dropout=0, mlp_dropout=0.1, batch_first=True, embedding_dropout=0.1, num_classes=1000, patch_embed: PatchEmbedding, msa: MultiheadSelfAttention, mlp: MLPBlock, encoder:TransformerEncoderBlock):
super().__init__()
assert self.hidden_size % self.patch_size == 0, "Image dimensions are wrong"
self.num_of_patches = (img_size * img_size) / (patch_size **2)
self.class_embedding = nn.Parameter(torch.randn(1, 1, hidden_size),
requires_grad=True)
self.position_embedding = nn.Parameter(torch.randn(1, self.num_of_patches+1, self.hidden_size), requires_grad=True)
self.embedding_dropout = nn.Dropout(p=embedding_dropout)
self.patch_embedding = patch_embed(
in_channels=in_channels,
patch_size=patch_size,
embedding_dim=hidden_size
)
self.vit = nn.Sequential(*[encoder(
hidden_size,
num_heads,
att_dropout,
batch_first,
mlp_size,
mlp_dropout,
msa,
mlp)
] for _ in range(num_layers))
self.classifier = nn.Sequential(
nn.LayerNorm(normalized_shape=hidden_size),
nn.Linear(in_features=hidden_size, out_features=num_classes)
)
def forward(self, X):
batch_size = X.shape[0]
class_token = self.class_embedding.expand(batch_size, -1, -1)
X = self.patch_embed(X)
X = torch.cat((class_token, X), dim=1)
X = self.position_embedding + X
X = self.embedding_dropout(X)
X = self.transformer_encoder(X)
X = self.classifier(X[:, 0])
return X